你的准备
今天依旧探究系统CPU使⽤率⾼的情况,所以这次实验的准备⼯作,与上节课的准备⼯作基本相同,差别在于案例所⽤的Docker 镜像不同。
本次还是基于 Ubuntu 18.04,同样适⽤于其他的 Linux 系统。我使⽤的案例环境如下所示:
机器配置:2 CPU,8GB 内存
预先安装 docker、sysstat、perf、ab 等⼯具,如 apt install docker.io sysstat linux-tools-common 。由于Nginx 和 PHP 的配置比较麻烦,我把它们打包成了两个 Docker 镜像,这样只需要运⾏两个容器,就可以得到模拟环境。注意,这个案例要⽤到两台虚拟机,如下图所示:
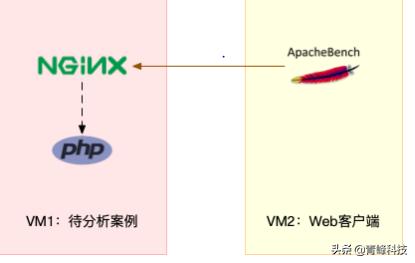
你可以看到,其中⼀台⽤作 Web 服务器,来模拟性能问题;另⼀台⽤作 Web 服务器的客户端,来给 Web 服务增加压⼒请求。使用两台虚拟机是为了相互隔离,避免“交叉感染”。
接下来,我们打开两个终端,分别 SSH 登录到两台机器上,并安装上述⼯具。
同样注意,下⾯所有命令都默认以 root ⽤户运⾏,如果你是⽤普通⽤户身份登陆系统,请运⾏ sudo su root 命令切换到 root ⽤户。
⾛到这⼀步,准备⼯作就完成了。接下来,我们正式进入操作环节。
温馨提示:案例中 PHP 应⽤的核⼼逻辑⽐较简单,你可能一眼就能看出问题,但实际生产环境中的源码就复杂多了。所以,我依旧建议,操作之前别看源码,避免先⼊为主,⽽要把它当成⼀个⿊盒来分析。这样,你可以更好把握,怎么从系统的资源使⽤问题出发,分析出瓶颈所在的应⽤,以及瓶颈在应⽤中⼤概的位置。
操作和分析⾸先,我们在第⼀个终端,执⾏下⾯的命令运⾏ Nginx 和 PHP 应⽤:
$ docker run --name nginx -p 10000:80 -itd feisky/nginx:sp
$ docker run --name phpfpm -itd --network container:nginx feisky/php-fpm:sp
然后,在第⼆个终端,使⽤ curl 访问 http://[VM1的IP]:10000,确认 Nginx 已正常启动。你应该可以看到 It works! 的响应。
# 192.168.0.10是第⼀台虚拟机的IP地址
$ curl http://192.168.0.10:10000/
It works!
接着,我们来测试一下这个 Nginx 服务的性能。在第⼆个终端运⾏下⾯的 ab 命令。要注意,与上次操作不同的是,这次我们
需要并发100个请求测试Nginx性能,总共测试1000个请求。# 并发100个请求测试Nginx性能,总共测试1000个请求
$ ab -c 100 -n 1000 http://192.168.0.10:10000/This is ApacheBench, Version 2.3 Copyright 1996 Adam Twiss, Zeus Technology Ltd,Requests per second: 87.86 [#/sec] (mean)Time per request: 1138.229 [ms] (mean)...
从ab的输出结果我们可以看到,Nginx能承受的每秒平均请求数,只有 87 多⼀点,是不是感觉它的性能有点差呀。那么,到底是哪⾥出了问题呢?我们再⽤ top 和 pidstat 来观察⼀下。
这次,我们在第⼆个终端,将测试的并发请求数改成5,同时把请求时⻓设置为10分钟(-t 600)。这样,当你在第⼀个终端
使⽤性能分析⼯具时, Nginx 的压⼒还是继续的。
继续在第⼆个终端运⾏ ab 命令:
$ ab -c 5 -t 600 http://192.168.0.10:10000/
然后,我们在第⼀个终端运⾏ top 命令,观察系统的 CPU 使⽤情况:
$ top
...
%Cpu(s): 80.8 us, 15.1 sy, 0.0 ni, 2.8 id, 0.0 wa, 0.0 hi, 1.3 si, 0.0 stPID USER PR NI VIRT RES SHR S %CPU %MEM TIME COMMAND6882 root 20 0 8456 5052 3884 S 2.7 0.1 0:04.78 docker-containe6947 systemd 20 0 33104 3716 2340 S 2.7 0.0 0:04.92 nginx7494 daemon 20 0 336696 15012 7332 S 2.0 0.2 0:03.55 php-fpm7495 daemon 20 0 336696 15160 7480 S 2.0 0.2 0:03.55 php-fpm10547 daemon 20 0 336696 16200 8520 S 2.0 0.2 0:03.13 php-fpm10155 daemon 20 0 336696 16200 8520 S 1.7 0.2 0:03.12 php-fpm10552 daemon 20 0 336696 16200 8520 S 1.7 0.2 0:03.12 php-fpm15006 root 20 0 1168608 66264 37536 S 1.0 0.8 9:39.51 dockerd4323 root 20 0 0 0 0 I 0.3 0.0 0:00.87 kworker/u4:1...
观察 top 输出的进程列表可以发现,CPU 使⽤率最⾼的进程也只不过才 2.7%,看起来并不⾼。
然⽽,再看系统 CPU 使⽤率( %Cpu )这⼀⾏,你会发现,系统的整体 CPU 使⽤率是⽐较⾼的:⽤户 CPU 使⽤率(us)
已经到了 80%,系统 CPU 为 15.1%,⽽空闲 CPU (id)则只有 2.8%。
为什么⽤户 CPU 使⽤率这么⾼呢?我们再重新分析⼀下进程列表,看看有没有可疑进程:docker-containerd 进程是⽤来运⾏容器的,2.7% 的 CPU 使⽤率看起来正常;
Nginx 和 php-fpm 是运⾏ Web 服务的,它们会占⽤⼀些 CPU 也不意外,并且 2% 的 CPU 使⽤率也不算⾼;
再往下看,后⾯的进程呢,只有 0.3% 的 CPU 使⽤率,看起来不太像会导致⽤户 CPU 使⽤率达到 80%。
那就奇怪了,明明⽤户 CPU 使⽤率都80%了,可我们挨个分析了⼀遍进程列表,还是找不到⾼ CPU 使⽤率的进程。看来top
是不管⽤了,那还有其他⼯具可以查看进程 CPU 使⽤情况吗?不知道你记不记得我们的⽼朋友 PIDstat,它可以⽤来分析进程
的 CPU 使⽤情况。
接下来,我们还是在第⼀个终端,运⾏ pidstat 命令:
# 间隔1秒输出⼀组数据(按Ctrl C结束)
$ pidstat 1
...
04:36:24 UID PID %usr %system %guest %wait %CPU CPU Command
04:36:25 0 6882 1.00 3.00 0.00 0.00 4.00 0 docker-containe
04:36:25 101 6947 1.00 2.00 0.00 1.00 3.00 1 nginx
04:36:25 1 14834 1.00 1.00 0.00 1.00 2.00 0 php-fpm
04:36:25 1 14835 1.00 1.00 0.00 1.00 2.00 0 php-fpm
04:36:25 1 14845 0.00 2.00 0.00 2.00 2.00 1 php-fpm
04:36:25 1 14855 0.00 1.00 0.00 1.00 1.00 1 php-fpm
04:36:25 1 14857 1.00 2.00 0.00 1.00 3.00 0 php-fpm
04:36:25 0 15006 0.00 1.00 0.00 0.00 1.00 0 dockerd
04:36:25 0 15801 0.00 1.00 0.00 0.00 1.00 1 pidstat
04:36:25 1 17084 1.00 0.00 0.00 2.00 1.00 0 stress
04:36:25 0 31116 0.00 1.00 0.00 0.00 1.00 0 atopacctd
...
观察⼀会⼉,你是不是发现,所有进程的 CPU 使⽤率也都不⾼啊,最⾼的 Docker 和 Nginx 也只有 4% 和 3%,即使所有进
程的 CPU 使⽤率都加起来,也不过是 21%,离 80% 还差得远呢!
最早的时候,我碰到这种问题就完全懵了:明明⽤户 CPU 使⽤率已经⾼达 80%,但我却怎么都找不到是哪个进程的问题。到
这⾥,你也可以想想,你是不是也遇到过这种情况?还能不能再做进⼀步的分析呢?
后来我发现,会出现这种情况,很可能是因为前⾯的分析漏了⼀些关键信息。你可以先暂停⼀下,⾃⼰往上翻,重新操作检查
⼀遍。或者,我们⼀起返回去分析 top 的输出,看看能不能有新发现。
现在,我们回到第⼀个终端,重新运⾏ top 命令,并观察⼀会⼉:$ top
top - 04:58:24 up 14 days, 15:47, 1 user, load average: 3.39, 3.82, 2.74
Tasks: 149 total, 6 running, 93 sleeping, 0 stopped, 0 zombie
%Cpu(s): 77.7 us, 19.3 sy, 0.0 ni, 2.0 id, 0.0 wa, 0.0 hi, 1.0 si, 0.0 st
KiB Mem : 8169348 total, 2543916 free, 457976 used, 5167456 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 7363908 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME COMMAND
6947 systemd 20 0 33104 3764 2340 S 4.0 0.0 0:32.69 nginx
6882 root 20 0 12108 8360 3884 S 2.0 0.1 0:31.40 docker-containe
15465 daemon 20 0 336696 15256 7576 S 2.0 0.2 0:00.62 php-fpm
15466 daemon 20 0 336696 15196 7516 S 2.0 0.2 0:00.62 php-fpm
15489 daemon 20 0 336696 16200 8520 S 2.0 0.2 0:00.62 php-fpm
6948 systemd 20 0 33104 3764 2340 S 1.0 0.0 0:00.95 nginx
15006 root 20 0 1168608 65632 37536 S 1.0 0.8 9:51.09 dockerd
15476 daemon 20 0 336696 16200 8520 S 1.0 0.2 0:00.61 php-fpm
15477 daemon 20 0 336696 16200 8520 S 1.0 0.2 0:00.61 php-fpm
24340 daemon 20 0 8184 1616 536 R 1.0 0.0 0:00.01 stress
24342 daemon 20 0 8196 1580 492 R 1.0 0.0 0:00.01 stress
24344 daemon 20 0 8188 1056 492 R 1.0 0.0 0:00.01 stress
24347 daemon 20 0 8184 1356 540 R 1.0 0.0 0:00.01 stress
...
这次从头开始看 top 的每⾏输出,咦?Tasks 这⼀⾏看起来有点奇怪,就绪队列中居然有 6 个 Running 状态的进程(6
running),是不是有点多呢?
回想⼀下 ab 测试的参数,并发请求数是 5。再看进程列表⾥, php-fpm 的数量也是 5,再加上 Nginx,好像同时有 6 个进程
也并不奇怪。但真的是这样吗?
再仔细看进程列表,这次主要看 Running(R) 状态的进程。你有没有发现, Nginx 和所有的 php-fpm 都处于Sleep(S)状
态,⽽真正处于 Running(R)状态的,却是⼏个 stress 进程。这⼏个 stress 进程就⽐较奇怪了,需要我们做进⼀步的分析。
我们还是使⽤ pidstat 来分析这⼏个进程,并且使⽤ -p 选项指定进程的 PID。⾸先,从上⾯ top 的结果中,找到这⼏个进程的PID。⽐如,先随便找⼀个 24344,然后⽤ pidstat 命令看⼀下它的 CPU 使⽤情况:
$ pidstat -p 24344
16:14:55 UID PID %usr %system %guest %wait %CPU CPU Command
奇怪,居然没有任何输出。难道是pidstat 命令出问题了吗?之前我说过,在怀疑性能⼯具出问题前,最好还是先⽤其他⼯具
交叉确认⼀下。那⽤什么⼯具呢? ps 应该是最简单易⽤的。我们在终端⾥运⾏下⾯的命令,看看 24344 进程的状态:# 从所有进程中查找PID是24344的进程
$ ps aux | grep 24344
root 9628 0.0 0.0 14856 1096 pts/0 S 16:15 0:00 grep --color=auto 24344
还是没有输出。现在终于发现问题,原来这个进程已经不存在了,所以 pidstat 就没有任何输出。既然进程都没了,那性能问
题应该也跟着没了吧。我们再⽤ top 命令确认⼀下:
$ top
...
%Cpu(s): 80.9 us, 14.9 sy, 0.0 ni, 2.8 id, 0.0 wa, 0.0 hi, 1.3 si, 0.0 st
...
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME COMMAND
6882 root 20 0 12108 8360 3884 S 2.7 0.1 0:45.63 docker-containe
6947 systemd 20 0 33104 3764 2340 R 2.7 0.0 0:47.79 nginx
3865 daemon 20 0 336696 15056 7376 S 2.0 0.2 0:00.15 php-fpm
6779 daemon 20 0 8184 1112 556 R 0.3 0.0 0:00.01 stress
...
好像⼜错了。结果还跟原来⼀样,⽤户 CPU 使⽤率还是⾼达 80.9%,系统 CPU 接近 15%,⽽空闲 CPU 只有
2.8%,Running 状态的进程有 Nginx、stress等。
可是,刚刚我们看到stress 进程不存在了,怎么现在还在运⾏呢?再细看⼀下 top 的输出,原来,这次 stress 进程的 PID 跟
前⾯不⼀样了,原来的 PID 24344 不⻅了,现在的是 6779。
进程的 PID 在变,这说明什么呢?在我看来,要么是这些进程在不停地重启,要么就是全新的进程,这⽆⾮也就两个原因:
第⼀个原因,进程在不停地崩溃重启,⽐如因为段错误、配置错误等等,这时,进程在退出后可能⼜被监控系统⾃动重启了。
第⼆个原因,这些进程都是短时进程,也就是在其他应⽤内部通过 exec 调⽤的外⾯命令。这些命令⼀般都只运⾏很短的时
间就会结束,你很难⽤ top 这种间隔时间⽐较⻓的⼯具发现(上⾯的案例,我们碰巧发现了)。
⾄于 stress,我们前⾯提到过,它是⼀个常⽤的压⼒测试⼯具。它的 PID 在不断变化中,看起来像是被其他进程调⽤的短时
进程。要想继续分析下去,还得找到它们的⽗进程。
要怎么查找⼀个进程的⽗进程呢?没错,⽤ pstree 就可以⽤树状形式显示所有进程之间的关系:
$ pstree | grep stress
|-docker-containe- -php-fpm- -php-fpm---sh---stress
| |-3*[php-fpm---sh---stress---stress]
从这⾥可以看到,stress 是被 php-fpm 调⽤的⼦进程,并且进程数量不⽌⼀个(这⾥是3个)。找到⽗进程后,我们能进⼊
app 的内部分析了。⾸先,当然应该去看看它的源码。运⾏下⾯的命令,把案例应⽤的源码拷⻉到 app ⽬录,然后再执⾏ grep 查找是不是有代码
再调⽤ stress 命令:
# 拷⻉源码到本地
$ docker cp phpfpm:/app .
# grep 查找看看是不是有代码在调⽤stress命令
$ grep stress -r app
app/index.php:// fake I/O with stress (via write()/unlink()).
app/index.php:$result = exec("/usr/local/bin/stress -t 1 -d 1 2>&1", $output, $status);
找到了,果然是 app/index.php ⽂件中直接调⽤了 stress 命令。
再来看看 app/index.php 的源代码:
$ cat app/index.php
// fake I/O with stress (via write()/unlink()).
$result = exec("/usr/local/bin/stress -t 1 -d 1 2>&1", $output, $status);
if (isset($_GET["verbose"]) && $_GET["verbose"]==1 && $status != 0) {
echo "Server internal error: ";
print_r($output);
} else {
echo "It works!";
}
?>
可以看到,源码⾥对每个请求都会调⽤⼀个 stress 命令,模拟 I/O 压⼒。从注释上看,stress 会通过 write() 和 unlink() 对 I/O进程进⾏压测,看来,这应该就是系统 CPU 使⽤率升⾼的根源了。
不过,stress 模拟的是 I/O 压⼒,⽽之前在 top 的输出中看到的,却⼀直是⽤户 CPU 和系统 CPU 升⾼,并没⻅到 iowait 升⾼。这⼜是怎么回事呢?stress 到底是不是 CPU 使⽤率升⾼的原因呢?
我们还得继续往下⾛。从代码中可以看到,给请求加⼊ verbose=1 参数后,就可以查看 stress 的输出。你先试试看,在第⼆个终端运⾏:$ curl http://192.168.0.10:10000?verbose=1
Server internal error: Array
(
[0] => stress: info: [19607] dispatching hogs: 0 cpu, 0 io, 0 vm, 1 hdd
[1] => stress: FAIL: [19608] (563) mkstemp failed: Permission denied
[2] => stress: FAIL: [19607] (394)
[3] => stress: WARN: [19607] (396) now reaping child worker processes
[4] => stress: FAIL: [19607] (400) kill error: No such process
[5] => stress: FAIL: [19607] (451) failed run completed in 0s
)
看错误消息 mkstemp failed: Permission denied ,以及 failed run completed in 0s。原来 stress 命令并没有成功,它因为权
限问题失败退出了。看来,我们发现了⼀个 PHP 调⽤外部 stress 命令的 bug:没有权限创建临时⽂件。
从这⾥我们可以猜测,正是由于权限错误,⼤量的 stress 进程在启动时初始化失败,进⽽导致⽤户 CPU 使⽤率的升⾼。
分析出问题来源,下⼀步是不是就要开始优化了呢?当然不是!既然只是猜测,那就需要再确认⼀下,这个猜测到底对不对,是不是真的有⼤量的 stress 进程。该⽤什么⼯具或指标呢?
我们前⾯已经⽤了 top、pidstat、pstree 等⼯具,没有发现⼤量的 stress 进程。那么,还有什么其他的⼯具可以⽤吗?
还记得上⼀期提到的 perf 吗?它可以⽤来分析 CPU 性能事件,⽤在这⾥就很合适。依旧在第⼀个终端中运⾏ perf record -g
命令 ,并等待⼀会⼉(⽐如15秒)后按 Ctrl C 退出。然后再运⾏ perf report 查看报告:
# 记录性能事件,等待⼤约15秒后按 Ctrl C 退出
$ perf record -g
# 查看报告
$ perf report
这样,你就可以看到下图这个性能报告:你看,stress 占了所有CPU时钟事件的 77%,⽽ stress 调⽤调⽤栈中⽐例最⾼的,是随机数⽣成函数 random(),看来它的确
就是 CPU 使⽤率升⾼的元凶了。随后的优化就很简单了,只要修复权限问题,并减少或删除 stress 的调⽤,就可以减轻系统的 CPU 压⼒。

当然,实际⽣产环境中的问题⼀般都要⽐这个案例复杂,在你找到触发瓶颈的命令⾏后,却可能发现,这个外部命令的调⽤过程是应⽤核⼼逻辑的⼀部分,并不能轻易减少或者删除。
这时,你就得继续排查,为什么被调⽤的命令,会导致 CPU 使⽤率升⾼或 I/O 升⾼等问题。这些复杂场景的案例,我会在后⾯的综合实战⾥详细分析。
最后,在案例结束时,不要忘了清理环境,执⾏下⾯的 Docker 命令,停⽌案例中⽤到的 Nginx 进程:
$ docker rm -f nginx phpfpm
execsnoop
在这个案例中,我们使⽤了 top、pidstat、pstree 等⼯具分析了系统 CPU 使⽤率⾼的问题,并发现 CPU 升⾼是短时进程
stress 导致的,但是整个分析过程还是⽐较复杂的。对于这类问题,有没有更好的⽅法监控呢?
execsnoop 就是⼀个专为短时进程设计的⼯具。它通过 ftrace 实时监控进程的 exec() ⾏为,并输出短时进程的基本信息,包
括进程 PID、⽗进程 PID、命令⾏参数以及执⾏的结果。
⽐如,⽤ execsnoop 监控上述案例,就可以直接得到 stress 进程的⽗进程 PID 以及它的命令⾏参数,并可以发现⼤量的
stress 进程在不停启动:# 按 Ctrl C 结束
$ execsnoop
PCOMM PID PPID RET ARGS
sh 30394 30393 0
stress 30396 30394 0 /usr/local/bin/stress -t 1 -d 1
sh 30398 30393 0
stress 30399 30398 0 /usr/local/bin/stress -t 1 -d 1
sh 30402 30400 0
stress 30403 30402 0 /usr/local/bin/stress -t 1 -d 1
sh 30405 30393 0
stress 30407 30405 0 /usr/local/bin/stress -t 1 -d 1
...
execsnoop 所⽤的 ftrace 是⼀种常⽤的动态追踪技术,⼀般⽤于分析 Linux 内核的运⾏时⾏为,后⾯课程我也会详细介绍并
带你使⽤。
⼩结
碰到常规问题⽆法解释的 CPU 使⽤率情况时,⾸先要想到有可能是短时应⽤导致的问题,⽐如有可能是下⾯这两种情况。
第⼀,应⽤⾥直接调⽤了其他⼆进制程序,这些程序通常运⾏时间⽐较短,通过 top 等⼯具也不容易发现。
第⼆,应⽤本身在不停地崩溃重启,⽽启动过程的资源初始化,很可能会占⽤相当多的 CPU。
对于这类进程,我们可以⽤ pstree 或者 execsnoop 找到它们的⽗进程,再从⽗进程所在的应⽤⼊⼿,排查问题的根源
CPU鍗犵敤鐜囧緢楂橈紝浣嗘槸杩涚▼閲屼笉鏄剧ず杩欎釜杩涚▼鏄鎬庝箞鍥炰簨锛
鎵鏈夋e湪鎵ц岀殑杩涚▼鍦ㄨ$畻鏈洪噷閮借兘鐪嬪埌锛岃屼笖鍙浠ュ弽鏄燙PU鐨勫疄鏃跺埄鐢ㄦ儏鍐点備及璁¤繖浣嶆湅鍙嬫病鏈夋壘鍒版娴嬪拰鏌ョ湅鐨勬柟娉曪紝姝ゅ浘渚嬭存槑涓涓嬶細
windows绯荤粺鏌ョ湅CPU浣跨敤鐜囧拰鍏蜂綋鍒嗛厤鍦ㄥ摢浜涜繘绋嬮噷鐨勫伐鍏锋槸鈥淲indows浠诲姟绠$悊鍣鈥濄傛墦寮鏂规硶鏈夊緢澶氾紝姣旇緝鏂逛究鐨勪竴绉嶆槸锛岄紶鏍囧湪绯荤粺鐣岄潰鏈涓嬬鐨勯偅鏉″彨鍋氣滅姸鎬佹爮鈥濈殑浣嶇疆涓婏紝鍙抽敭鍙浠ョ湅鍒扳滃惎鍔ㄤ换鍔$$悊鍣ㄢ濈殑瀛楁牱閫夐」锛岀偣鍑昏繘鍏ワ紱
浠诲姟绠$悊鍣ㄥ紑鍚鐣岄潰濡備笅鍥炬墍绀猴細
浠庡浘涓鍙浠ユ竻妤氱湅鍒颁竴鍏辨e湪鍝嶅簲鐨勮繘绋嬫暟鏄68涓锛孋PU浣跨敤鐜17%銆傞粯璁ゆ墦寮鐨勯夐」鍗℃槸鈥搴旂敤绋嬪簭鈥濄傛垜浠鍙浠ラ夋嫨绗浜岄」鈥滆繘绋嬧濈湅鍏蜂綋鎯呭喌銆
3. 杩涚▼鐨勬儏鍐靛備笅鍥炬墍绀猴細
鎴戞寜鐓CPU浣跨敤鐜囧仛浜嗛檷搴忔帓搴忥紝鐒跺悗鍙浠ユ竻妤氱湅鍒扮涓椤光渟ystem idle鈥濆瓧鏍风殑杩涚▼浣跨敤鐜囨渶楂樸傝繖鏄绯荤粺鍩烘湰涓嶈繍琛屽ぇ绋嬪簭鏃剁殑姝e父鐘舵侊紝杩欎釜杩涚▼灏辨槸璐熻矗绯荤粺绌洪棽绛夊緟鐨勮繘绋嬨傝繕鑳界湅鍒版媿绗浜岀殑鏄疩Q锛屼絾涔熷彧鐢ㄤ簡绯荤粺3%鐨凜PU璧勬簮銆
鎸夌収杩欎釜鏂规硶锛屼綘鍙浠ヨ嚜宸辨壘鍒癈PU浣跨敤鐜囬珮鐨勬椂鍊欙紝鍏蜂綋浠涔堢▼搴忓拰杞浠跺崰鐢ㄤ簡纭浠惰祫婧愩傚苟閲囧彇鐩稿簲鎺鏂藉叧闂鎴栬呯佹銆

CPU鍗犵敤鐜囬珮锛岃繘绋嬪嵈鏌ヤ笉鍒
鍦ㄨ祫婧愮$悊鍣ㄤ腑鍒囧埌鈥滄ц兘鈥濓紝鐒跺悗鐐瑰嚮鍨嬭~鐮佲滄墦寮璧勬簮鐩戣嗗櫒鈥濆屼笡锛屽湪鍏朵腑鍒囧埌cpu锛岀偣鍑籧pu鍚嶇О鎺掑簭锛屽崪鍝鍙浠ョ湅鍒板疄闄呭崰鐢╟pu鐨勮繘绋嬨