本文为 AI 研习社编译的技术博客,原标题 :
BERT Technology introduced in 3-minutes
作者 | Suleiman Khan, Ph.D.
翻译 | 胡瑛皓、stone豪
校对 | 酱番梨 审核 | 约翰逊·李加薪 整理 | 立鱼王
原文链接:
https://towardsdatascience.com/bert-technology-introduced-in-3-minutes-2c2f9968268c
由谷歌公司出品的用于自然语言理解的预训练BERT算法,在许自然语言处理的任务表现上远远胜过了其他模型。
BERT算法的原理由两部分组成,第一步,通过对大量未标注的语料进行非监督的预训练,来学习其中的表达法。其次,使用少量标记的训练数据以监督方式微调预训练模型以进行各种监督任务。预训练机器学习模型已经在各种领域取得了成功,包括图像处理和自然语言处理(NLP)。
BERT的含义是Transformer的双向编码器表示。 它基于Transformer架构(由Google于2017年发布,《Attention Is All You Need》)。 Transformer算法使用编码-解码器网络,但是,由于BERT是预训练模型,它仅使用编码来学习输入文本中的潜在表达。

Photo by Franki Chamaki on Unsplash
技术BERT将多个transformer编码器堆叠在一起。tranformer基于著名的多头注意模块(multi-head attention)。 它在视觉和语言任务方面都取得了巨大成功。关于attention的回顾,请参考此处:
http://mlexplained.com/2017/12/29/attention-is-all-you-need-explained/
BERT卓越的性能基于两点。 首先创新预训练任务Masked Language Model (MLM)以及Next Sentence Prediction (NSP). 其次训练BERT使用了大量数据和算力。
MLM使得BERT能够从文本中进行双向学习,也就是说这种方式允许模型从单词的前后单词中学习其上下文关系。此前的模型这是做不到的。此前最优的算法称为Generative Pre-training (GPT) 该方法采用了从左到右的训练方式,另外ELMo 采用浅双向学习(shallow bidirectionality)。
MLM预训练任务将文本转换为tokens,把token表示作为训练的输入和输出。随机取其中15%的token进行mask,具体来说就是在训练输入时隐藏,然后用目标函数预测出正确的token内容。这种方式对比以往的训练方式,以往方式采用单方向预测作为目标或采用从左到右及从右到左两组(单方向)去近似双向。NSP任务通过预测后一个句子是否应该接在前一句之后,从而使得BERT可以学习句子间的关系。训练数据采用50%顺序正确的句子对加上另外50%随机选取的句子对。BERT同时训练MLM和NSP这两个目标。
数据及TPU/GPU运行时BERT训练使用了33亿单词以及25亿维基百科和8亿文本语料。训练采用TPU, GPU,大致情况如下.
BERT训练设备和时间 for BERT; 使用TPU数量和GPU估算.
Fine-tuning训练采用了2.5K~392K 标注样本。重要的是当训练数据集超过100K,在多种超参数设置下模型显示了其稳健的性能。每个fine-tuning实验采用单个TPU均在1小时内完成,GPU上需要几小时。
结果BERT在11项NLP任务中超越了最优的算法。主要是3类任务,文本分类、文字蕴涵和问答。BERT在SQUAD和SWAG任务中,是第一个超过人类水平的算法!
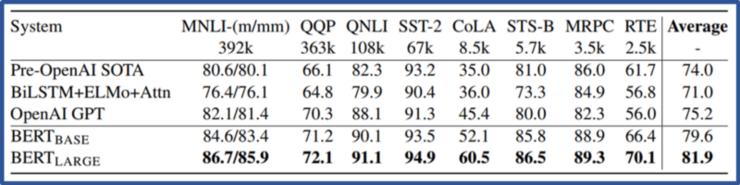
BERT 论文中结果 https://arxiv.org/abs/1810.04805
在分享中使用 BERTBERT目前已开源: https://github.com/google-research/bert 分别用TensorFlow和Pytorch预训练了104种语言。
模型可进行fine-tuned,然后用于多项NLP任务,诸如文本分类、文本相似度、问答系统、文本标记如词性POS命名和实体识别NER等。当然预训练BERT计算上相当昂贵,除非你采用TPU或类似Nvidia V100这样的GPU。
BERT技术人员同时也放出了多语言模型,模型采用Wikipedia里的100多种语言。不过多语言BERT模型比单语言模型的性能要略低几个百分点。
批判BERT在MLM任务中的mask策略对真实的单词产生偏见。目前还未显示这种偏见对训练的影响。
参考文献[1] https://cloud.google.com/tpu/docs/deciding-pod-versus-tpu
[2] Assuming second generation TPU, 3rd generation is 8 times faster. https://en.wikipedia.org/wiki/Tensor_processing_unit
[3] http://timdettmers.com/2018/10/17/tpus-vs-gpus-for-transformers-bert/
想要继续查看该篇文章相关链接和参考文献?
点击【三分钟带你读懂 BERT】或长按下方地址:雷锋网雷锋网雷锋网
https://ai.yanxishe.com/page/TextTranslation/1509
AI入门、大数据、机器学习免费教程
35本世界顶级原本教程限时开放,这类书单由知名数据科学网站 KDnuggets 的副主编,同时也是资深的数据科学家、深度学习技术爱好者的Matthew Mayo推荐,他在机器学习和数据科学领域具有丰富的科研和从业经验。
点击链接即可获取:https://ai.yanxishe.com/page/resourceDetail/417

05-ELMo/BERT/GPT-NLP预训练模型
这里可以参考CSDN上的文章-BERT原理和实践: https://blog.csdn.net/jiaowoshouzi/article/category/9060488
在解释BERT,ELMO这些预训练模型之前,我们先看一下很久之前的计算机是如何读懂文字的?
每个字都有自己的独特的编码。但是这样是有弊端的,字和字之间的关联关系是无法得知的,比如计算机无法知道dog和cat都是动物,它反而会觉得bag和dog是比较相近的。
所以后来就有了Word Class,将一系列的词进行分类然后让一类词语和一类词语之间更有关联,但是这样的方法太过于粗糙,比如dog,cat,bird是一类,看不出哺乳动物鸟类的区别。
在这个基础之上,我们有了Word Embedding,Word Embedding我们可以想象成是一种soft的word class,每个词都用向量来表示,它的向量维度可能表示这个词汇的某种意思,如图中dog,cat,rabbit的距离相比其他更近。那么word embendding是如何训练出来的,是根据每个词汇的上下文所训练的。
每个句子都有bank的词汇,四个bank是不同的token,但是同样的type。(注:token-词例, type-词型, class-词类 or token是出现的总次数(还有种理解是token是具有一定的句法语义且独立的最小文本成分。 ),type是出现的不同事物的个数。)
对于典型的Word Embedding认为,每个词type有一个embedding,所以就算是不同的token只要是一样的type那么word embedding就是一样的,语义也就是一样的。
而事实上并非如此,1,2句bank指的是银行,3,4为水库。所以我们希望让机器给不同意思的token而且type还一致,给予不同的embedding。在这个问题上,之前的做法是从字典中去查找这个词包含几种意思,但是这样的做法显然跟不上现实中词语的一些隐含的含义。比如bank有银行的意思,与money一起是银行的意思,而与blood一起却是血库的意思。
所以我们想让机器今天进一步做到每一个word token都可以有自己的embedding(之前是每个type有一个embedding或者有固定的一个或多个embedding),那么怎么知道一个word应该有怎样的embedding呢?我们可以取决于该词的上下文,上下文越相近的token它们就会越相近的embedding。比如之前提到的bank,下面两个句子它们的word token的embedding可能是相近的,而和上面的word token的embedding是相远的。
所以我们想使用一种能够基于上下文的Contextual word Embedding来解决一词多义的问题。
这里使用ELMO可以做到这件事情,即每个word token拥有不同的word embedding。(右上角动物是芝麻街(美国公共广播协会(PBS)制作播出的儿童教育电视节目)里的角色)。
它是基于RNN的预训练模型,它只需要搜集大量语料(句子)且不需要做任何标注,就可以训练这个基于RNN的语言模型,预测下一个token是什么,学习完了之后就得到了上下文的embedding。因为我们可以将RNN的隐藏层中的某一节点拿出来(图中橙蓝色节点),它就是输入当前结点的词汇的word embedding。
从当计算识别到<BOS>,模型训练开始。首先输入"潮水",然后当作输入输出"退了",退了当做输入输出"就"。
假设当前要得到”退了”这个词的上下文embedding,首先,因为前边的RNN只考虑到了前文而没有考虑到后文,所以这里就使用了同前文一样的反向的RNN。然后,它从句尾开始进行,比如给它喂”知道”,它就要预测”就”,给它喂”就”,它就要预测”退了”。这时候就不仅考虑每个词汇的前文,还会考虑每个词的后文。最后将正向和逆向得到的两个不同的上下文embedding(因为方向不同训练结果也不一样)拼接起来。
现在我们训练的程度都会越来越深度,当层数增加,这样就会产生Deep的RNN,因为很多层,而且每一层都会产生上下文Embedding,那么我们到底应该使用哪一层?每一层这种深度LSTM中的每个层都可以生成潜在表示(方框处)。同一个词在不同的层上会产生不同的Embedding,那么我们应该使用哪一层呢?ELMo的策略是每一层得到的上下文embedding都要。
在上下文embedding的训练模型中,每个词输入进去都会有一个embedding输出来。但是在ELMo中,每个词汇输入进去,都会得到不止一个embedding,因为每层的RNN都会给到一个embedding,ELMo将它们统统加起来一起使用。
以图中为例,这里假设ELMo有两层RNN,这里是将α1(黄色,第一层得到的embedding)和α2(绿色,第二层得到embedding)加起来得到蓝色的embedding,并做为接下来要进行不同任务的输入。
但是这里存在一些问题,α1和α2是学习得到的,而且它是根据当前要进行的任务(如QA,POS of tagging ),然后根据接下来要进行的这些任务一起被学习出来。所以就导致不同任务导向下的α1和α2也不一样。
ELMo的论文中提到,在不同任务下(SRL,Coref,SNLI,SQuAD,SST-5)。蓝色的上下文embedding在经过token(这里为没有经过上下文的embedding),LSTM1,LSTM2后,它在不同阶段需要的weight也不一样。
BERT相当于是Transformer的Encoder部分,它只需要搜集大量的语料去从中学习而不经过标注(不需要label),就可以将Encoder训练完成。如果之前要训练Encoder,我们需要通过一些任务来驱动学习(如机器翻译)。
BERT就是句子给进去,每个句子给一个embedding。
这里可以回忆下,Transformer的Enoder中有self-attention layer,就是给进去一个sequence,输出也得到一个sequence。
虽然图中使用是用词作为单元进行输入,但是在使用BERT进行中文的训练时,字会是一个更好的选择。比如,我们在给BERT进行输入时,用one-hot给词进行编码,但是词在中文中数量庞大,会导致维度过高。但是,字的话相对会少很多,特别是中文(大约几千个,可以穷举)。这样以字为单位进行输入会占很大优势。
共有两种方法,一种是Mask LM遮盖语言模型,另一种是Next Sentence Prediction下一句预测。
下面用上图的例子来理解BERT是怎么样来进行填空的:
1)这里假设在所有句子中的词汇的第2个位置上设置一个<MASK>;
2)接下来把所有的词汇输入BERT,然后每个输入的token都会得到一个embedding;
3)接下来将设置为<MASK>的embedding输入到Linear Multi-class Classifier中中,要求它预测被<MASK>的词汇是哪个词汇?
但是这个Linear Multi-class Classifier它仅仅是一个线性分类器,所以它的能力十分弱,这也就需要在之前的BERT模型中需要将它的层数等参数设计的相当好,然后得到非常出色的representation,便于线性分类器去训练。
那么我们怎么知道最后得到的embedding是什么样的呢?如果两个<MASK>下的词汇(输入时设置的<MASK>和最后预测的<MASK>)都放回原来的位置而且没有违和感(就是语句还算通顺),那它们就有类似的embedding(比如退下和落下)。
如图中,给定两个句子1)醒醒吧 和 2)你没有妹妹。其中特殊符号[SEP]是告诉BERT两个句子的分隔点在哪里。
特殊符号[CLS]一般放在句子的开头,它用来告诉BERT从这开始分类任务,[CLS]输入BERT后得到embedding然后通过Linear Binary Classifier得出结果说明:经过BERT预测后现在我们要预测的两个句子是接在一起 or 不应该被接在一起。
这里可能会有疑问,为什么不将[CLS]放在句尾,等BERT训练完两个句子再输出结果?
对于上图中的任务,BERT现在要做的事情就是给定两个句子,让BERT输出结果这两个句子是不是应该接在一起?
所以在语料库的大量句子中,我们是知道哪些句子是可以接在一起的,所以也需要我们告诉BERT哪些句子是接在一起的。
Linear Binary Classifier和BERT是一起被训练的,通过预测下一句这个任务,我们就可以把将BERT部分的最优参数训练出来。
现在我们知道了任务一和任务二,在原论文中两种任务是要同时进行的,这样才能将BERT的性能发挥到最佳。
现在我们知道了BERT要做什么事情,那么我们要如何去使用它?共有四种方法。论文中是将【BERT模型和接下来你要进行的任务】结合在一起做训练。
第一种,假设当前任务是Input一个sentence,out一个class,举例来说输入一句话来判断分类。
训练流程:1)将做要分类的句子丢给BERT;
2)需要在句子开始加上分类的特殊符号,这个特殊符号经过BERT输出的embedding经过线性分类器,输出结果为当前的句子属于的类别是真还是假。BERT和Linear Classifier的参数一起进行学习;
3)这里的Linear Classifier是Trained from Scratch是白手起家从头开始,即它的参数随机初始化设置,然后开始训练;
4)而BERT则是加上Fine-tune微调策略(一种迁移学习方式*),例如Generative Pre-trained Transformer(OpenAI GPT生成型预训练变换器)(Radford等,2018),引入了最小的任务特定参数,并通过简单地微调预训练参数在下游任务中进行训练。
*这里不得不提一下迁移学习中的Fine-tune,这里可以参考csdn的一篇文章: https://blog.csdn.net/u013841196/article/details/80919857
( https://arxiv.org/abs/1805.12471 )
第二种,假设当前任务是input一个sentence,输出这个句子中的每个词汇属于正例还是负例。举例现在的任务是slot filling填槽任务(填槽指的是为了让用户意图转化为用户明确的指令而补全信息的过程)(另一种解释是从大规模的语料库中抽取给定实体(query)的被明确定义的属性(slot types)的值(slot fillers))(槽可以理解为实体已明确定义的属性),输入的句子是 arrive Taipei on November 2nd输出的槽是other dest on time time
训练流程:
1)将句子输入BERT,句子中的每个词汇都会映射出一个embedding;
2)每个词汇的embedding输入Linear Classifier,输出结果;
3)Linear Classifier 白手起家和Bert微调的方式一起去做学习。
第三种,假设当前任务是input输入两个句子,输出class。举例现在要进行自然语言预测,让机器根据premise前提,预测这个hypothesis假设是True还是False还是unknown不知道。实际上,我们可以把这个任务当成三分类问题。
训练过程:
1)在一个sentence前设置特殊符号[CLS],然后在要输入的两个sentence中间设置[SEP]分隔符号;
2)将两个sentence连同特殊符号一起输入到BERT中;
3)将[CLS]输入BERT后得到的embedding,再把它输入linear Classifier中,得到class。
如图所示,假设gravity的token序号是17,即 ,我们现在有一个问题通过QA Model后得到的s=17,e=17,那么答案就是 为gravity;
同理,假设within a cloud的序号顺序是77到79,即 到 ,我们现在有一个问题通过QA Model后得到的s=77,e=79,那么答案就是 为within a cloud。
https://arxiv.org/abs/1905.05950
https://openreview.net/pdf?id=SJzSgnRcKX
这张图显示了BERT从0-24层的层数在针对不同的NLP任务上的表现。
https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
而所谓的GPT,它其实就是Transformer的Decoder。
我们简单的描述下GPT的训练过程:这里我们input<BOS>这个token和潮水,想要GPT预测输出“退了”这个词汇。
1)首先输入[BOS](begin of sentence)和潮水,通过Word Embedding再乘上matrix W变成a 1到a 4,然后把它们丢进self-attention 层中,这时候每一个input都分别乘上3个不同的matrix产生3个不同的vector,分别把它们命名为q,k,v。
q代表的是query (to match others用来去匹配其它的向量)
k代表的是key (to be matched用来去被query匹配的向量)
v代表的是value(information to be extracted用来被抽取的信息的向量)
2)现在要做的工作就是用每个query q 去对每个 key k做attention(吃2个向量,输出就是告诉你这2个向量有多么匹配或者可以说输入两个向量输出一个分数\alpha(而怎么去吃2个向量output一个分数,有很多不同的做法))。这里要预测潮水的下一个词,所以乘 , 乘上 , 乘上 再经过soft-max分别得到 到 。
3)我们用 和每一个v相乘, 和 相乘加上 和 相乘。以此类推并相加,最终得到 。
4)然后经过很多层的self-attention,预测得到”退了”这个词汇。
同理,现在要预测”退了”的下一个词汇,按照前面的流程可以得到 ,然后经过很多层的self-attention层,得到”就”这个词汇。
GPT的神奇之处在于它可以在完全没有训练数据的情况下,就可以做到阅读理解,摘要,翻译。折线图中显示了它在参数量上升的情况下,F1的值的效果。
1.Transformer的问题:
word Embedding 无上下文
监督数据太少
解决方法:
Contextual Word Embedding
2.ELMo( E mbeddings from L anguages Mo del)
- 多层双向的LSTM的NNLM
- RNN-based language models(trained from lots of sentences)
ELMo的问题:
Contextual Word Embedding作为特征
不适合特定任务
3.OpenAI GPT的改进
根据任务Fine-Tuning
使用Transformer替代RNN/LSTM
OpenAI GPT的问题:
单向信息流的问题
Pretraining(1)和Fine-Tuning(2)不匹配
解决办法:
Masked LM
NSP Multi-task Learning
Encoder again
Tips:
- 使用中文模型
- max_seq_length可以小一点,提高效率
- 内存不够,需要调整train_batch_size
- 有足够多的领域数据,可以尝试Pretraining

一文读懂神经网络
要说近几年最引人注目的技术,无疑的,非人工智能莫属。无论你是否身处科技互联网行业,随处可见人工智能的身影:从 AlphaGo 击败世界围棋冠军,到无人驾驶概念的兴起,再到科技巨头 All in AI,以及各大高校向社会输送海量的人工智能专业的毕业生。以至于人们开始萌生一个想法:新的革命就要来了,我们的世界将再次发生一次巨变;而后开始焦虑:我的工作是否会被机器取代?我该如何才能抓住这次革命?
人工智能背后的核心技术是深度神经网络(Deep Neural Network),大概是一年前这个时候,我正在回老家的高铁上学习 3Blue1Brown 的 Neural Network 系列视频课程,短短 4 集 60 多分钟的时间,就把神经网络从 High Level 到推导细节说得清清楚楚,当时的我除了获得新知的兴奋之外,还有一点新的认知,算是给头脑中的革命性的技术泼了盆冷水:神经网络可以解决一些复杂的、以前很难通过写程序来完成的任务——例如图像、语音识别等,但它的实现机制告诉我,神经网络依然没有达到生物级别的智能,短期内期待它来取代人也是不可能的。
一年后的今天,依然在这个春运的时间点,将我对神经网络的理解写下来,算是对这部分知识的一个学习笔记,运气好的话,还可以让不了解神经网络的同学了解起来。
维基百科这样解释 神经网络 :
这个定义比较宽泛,你甚至还可以用它来定义其它的机器学习算法,例如之前我们一起学习的逻辑回归和 GBDT 决策树。下面我们具体一点,下图是一个逻辑回归的示意图:
其中 x1 和 x2 表示输入,w1 和 w2 是模型的参数,z 是一个线性函数:
接着我们对 z 做一个 sigmod 变换(图中蓝色圆),得到输出 y:
其实,上面的逻辑回归就可以看成是一个只有 1 层 输入层 , 1 层 输出层 的神经网络,图中容纳数字的圈儿被称作 神经元 ;其中,层与层之间的连接 w1、w2 以及 b,是这个 神经网络的参数 ,层之间如果每个神经元之间都保持着连接,这样的层被称为 全连接层 (Full Connection Layer),或 稠密层 (Dense Layer);此外,sigmoid 函数又被称作 激活函数 (Activation Function),除了 sigmoid 外,常用的激活函数还有 ReLU、tanh 函数等,这些函数都起到将线性函数进行非线性变换的作用。我们还剩下一个重要的概念: 隐藏层 ,它需要把 2 个以上的逻辑回归叠加起来加以说明:
如上图所示,除输入层和输出层以外,其他的层都叫做 隐藏层 。如果我们多叠加几层,这个神经网络又可以被称作 深度神经网络 (Deep Neural Network),有同学可能会问多少层才算“深”呢?这个没有绝对的定论,个人认为 3 层以上就算吧:)
以上,便是神经网络,以及神经网络中包含的概念,可见,神经网络并不特别,广义上讲,它就是
可见,神经网络和人脑神经也没有任何关联,如果我们说起它的另一个名字—— 多层感知机(Mutilayer Perceptron) ,就更不会觉得有多么玄乎了,多层感知机创造于 80 年代,可为什么直到 30 年后的今天才爆发呢?你想得没错,因为改了个名字……开个玩笑;实际上深度学习这项技术也经历过很长一段时间的黑暗低谷期,直到人们开始利用 GPU 来极大的提升训练模型的速度,以及几个标志性的事件:如 AlphaGo战胜李世石、Google 开源 TensorFlow 框架等等,感兴趣的同学可以翻一下这里的历史。
就拿上图中的 3 个逻辑回归组成的神经网络作为例子,它和普通的逻辑回归比起来,有什么优势呢?我们先来看下单逻辑回归有什么劣势,对于某些情况来说,逻辑回归可能永远无法使其分类,如下面数据:
这 4 个样本画在坐标系中如下图所示
因为逻辑回归的决策边界(Decision Boundary)是一条直线,所以上图中的两个分类,无论你怎么做,都无法找到一条直线将它们分开,但如果借助神经网络,就可以做到这一点。
由 3 个逻辑回归组成的网络(这里先忽略 bias)如下:
观察整个网络的计算过程,在进入输出层之前,该网络所做的计算实际上是:
即把输入先做了一次线性变换(Linear Transformation),得到 [z1, z2] ,再把 [z1, z2] 做了一个非线性变换(sigmoid),得到 [x1', x2'] ,(线性变换的概念可以参考 这个视频 )。从这里开始,后面的操作就和一个普通的逻辑回归没有任何差别了,所以它们的差异在于: 我们的数据在输入到模型之前,先做了一层特征变换处理(Feature Transformation,有时又叫做特征抽取 Feature Extraction),使之前不可能被分类的数据变得可以分类了 。
我们继续来看下特征变换的效果,假设 为 ,带入上述公式,算出 4 个样本对应的 [x1', x2'] 如下:
再将变换后的 4 个点绘制在坐标系中:
显然,在做了特征变换之后,这两个分类就可以很容易的被一条决策边界分开了。
所以, 神经网络的优势在于,它可以帮助我们自动的完成特征变换或特征提取 ,尤其对于声音、图像等复杂问题,因为在面对这些问题时,人们很难清晰明确的告诉你,哪些特征是有用的。
在解决特征变换的同时,神经网络也引入了新的问题,就是我们需要设计各式各样的网络结构来针对性的应对不同的场景,例如使用卷积神经网络(CNN)来处理图像、使用长短期记忆网络(LSTM)来处理序列问题、使用生成式对抗网络(GAN)来写诗和作图等,就连去年自然语言处理(NLP)中取得突破性进展的 Transformer/Bert 也是一种特定的网络结构。所以, 学好神经网络,对理解其他更高级的网络结构也是有帮助的 。
上面说了,神经网络可以看作一个非线性函数,该函数的参数是连接神经元的所有的 Weights 和 Biases,该函数可以简写为 f(W, B) ,以手写数字识别的任务作为例子:识别 MNIST 数据集 中的数字,数据集(MNIST 数据集是深度学习中的 HelloWorld)包含上万张不同的人写的数字图片,共有 0-9 十种数字,每张图片为 28*28=784 个像素,我们设计一个这样的网络来完成该任务:
把该网络函数所具备的属性补齐:
接下来的问题是,这个函数是如何产生的?这个问题本质上问的是这些参数的值是怎么确定的。
在机器学习中,有另一个函数 c 来衡量 f 的好坏,c 的参数是一堆数据集,你输入给 c 一批 Weights 和 Biases,c 输出 Bad 或 Good,当结果是 Bad 时,你需要继续调整 f 的 Weights 和 Biases,再次输入给 c,如此往复,直到 c 给出 Good 为止,这个 c 就是损失函数 Cost Function(或 Loss Function)。在手写数字识别的列子中,c 可以描述如下:
可见,要完成手写数字识别任务,只需要调整这 12730 个参数,让损失函数输出一个足够小的值即可,推而广之,绝大部分神经网络、机器学习的问题,都可以看成是定义损失函数、以及参数调优的问题。
在手写识别任务中,我们既可以使用交叉熵(Cross Entropy)损失函数,也可以使用 MSE(Mean Squared Error)作为损失函数,接下来,就剩下如何调优参数了。
神经网络的参数调优也没有使用特别的技术,依然是大家刚接触机器学习,就学到的梯度下降算法,梯度下降解决了上面迭代过程中的遗留问题——当损失函数给出 Bad 结果时,如何调整参数,能让 Loss 减少得最快。
梯度可以理解为:
把 Loss 对应到 H,12730 个参数对应到 (x,y),则 Loss 对所有参数的梯度可以表示为下面向量,该向量的长度为 12730:
$$
\nabla L(w,b) = \left[
\frac{\partial L}{\partial w_1},
\frac{\partial L}{\partial w_2},...,
\frac{\partial L}{\partial b_{26}}
\right] ^\top
$$
所以,每次迭代过程可以概括为
用梯度来调整参数的式子如下(为了简化,这里省略了 bias):
上式中, 是学习率,意为每次朝下降最快的方向前进一小步,避免优化过头(Overshoot)。
由于神经网络参数繁多,所以需要更高效的计算梯度的算法,于是,反向传播算法(Backpropagation)呼之欲出。
在学习反向传播算法之前,我们先复习一下微积分中的链式法则(Chain Rule):设 g = u(h) , h = f(x) 是两个可导函数,x 的一个很小的变化 △x 会使 h 产生一个很小的变化 △h,从而 g 也产生一个较小的变化 △g,现要求 △g/△x,可以使用链式法则:
有了以上基础,理解反向传播算法就简单了。
假设我们的演示网络只有 2 层,输入输出都只有 2 个神经元,如下图所示:
其中 是输入, 是输出, 是样本的目标值,这里使用的损失函数 L 为 MSE;图中的上标 (1) 或 (2) 分别表示参数属于第 (1) 层或第 (2) 层,下标 1 或 2 分别表示该层的第 1 或 第 2 个神经元。
现在我们来计算 和 ,掌握了这 2 个参数的偏导数计算之后,整个梯度的计算就掌握了。
所谓反向传播算法,指的是从右向左来计算每个参数的偏导数,先计算 ,根据链式法则
对左边项用链式法则展开
又 是输出值, 可以直接通过 MSE 的导数算出:
而 ,则 就是 sigmoid 函数的导数在 处的值,即
于是 就算出来了:
再来看 这一项,因为
所以
注意:上面式子对于所有的 和 都成立,且结果非常直观,即 对 的偏导为左边的输入 的大小;同时,这里还隐含着另一层意思:需要调整哪个 来影响 ,才能使 Loss 下降得最快,从该式子可以看出,当然是先调整较大的 值所对应的 ,效果才最显著 。
于是,最后一层参数 的偏导数就算出来了
我们再来算上一层的 ,根据链式法则 :
继续展开左边这一项
你发现没有,这几乎和计算最后一层一摸一样,但需要注意的是,这里的 对 Loss 造成的影响有多条路径,于是对于只有 2 个输出的本例来说:
上式中, 都已经在最后一层算出,下面我们来看下 ,因为
于是
同理
注意:这里也引申出梯度下降的调参直觉:即要使 Loss 下降得最快,优先调整 weight 值比较大的 weight。
至此, 也算出来了
观察上式, 所谓每个参数的偏导数,通过反向传播算法,都可以转换成线性加权(Weighted Sum)计算 ,归纳如下:
式子中 n 代表分类数,(l) 表示第 l 层,i 表示第 l 层的第 i 个神经元。 既然反向传播就是一个线性加权,那整个神经网络就可以借助于 GPU 的矩阵并行计算了 。
最后,当你明白了神经网络的原理,是不是越发的认为,它就是在做一堆的微积分运算,当然,作为能证明一个人是否学过微积分,神经网络还是值得学一下的。Just kidding ..
本文我们通过
这四点,全面的学习了神经网络这个知识点,希望本文能给你带来帮助。
参考: